10 miesięcy temu
10 miesięcy temu
Od czasu do czasu Internet obiega wieść o dużym wycieku danych użytkowników jakiegoś serwisu. To, iż tak się dzieje nie powinno już nikogo zaskakiwać. Dla niektórych ewentualnym zaskoczeniem może być skala i częstotliwość tego zjawiska.
Warto też nadmienić, iż wyciek wyciekowi nie równy i czasem wyciekiem nazywa się zbiór danych, który tak na prawdę nim nie jest, a stanowi jedynie kompilację różnych wycieków albo wręcz pojedynczych rekordów danych wykradanych użytkownikom zainfekowanym jakimś złośliwym oprogramowaniem. To, co funkcjonuje pod hasłem wycieków możemy więc podzielić na kilka kategorii:
- Rzeczywiste wycieki, czyli bazy wykradane konkretnym usługodawcom zawierające dane ich klientów (takie jak np. głośny wyciek z serwisu morele.net)
- Dane pochodzące ze stealerów – tzw. stealer logi – zbiory będące efektem działania złośliwego oprogramowania, które z zainfekowanych komputerów wyciąga hasła zapisane w przeglądarkach. Tutaj przykładem jest ujawniony niedawno na niesławnym forum Cebulka plik zawierający 6 mln. haseł Polaków (nie do końca, ale o tym później)
- Dane pochodzące z kampanii phishingowych, czyli hasła przechwycone na fałszywych stronach podszywających się pod znanych usługodawców.
- Tzw. combo/combosy, czyli kompilacje, których autorzy łączą w jeden ogromny zbiór dane pochodzące z różnych źródeł. Tutaj przykładem może być zbiór Collection1 zawierający dane z ponad 2 tys. innych wycieków, ale też nowe, nie odnotowane wcześniej dane.
Gdzie publikowane są wycieki danych?
Najczęściej w dark necie, chociaż dane takie można znaleźć również na łatwiej dostępnych forach (np. LeakBase), torrentach, a choćby GitHubie. Celowo nie podaję tutaj linków bo po pierwsze w miejscach takich można niechcący trafić na jakąś złośliwą zawartość, a po drugie nie chcę być posądzony o dystrybucję nielegalnych treści.
Żeby jednak uzmysłowić Wam jak częste jest to zjawisko i na jak dużą skalę dochodzi do takich wycieków zamieszczam kilka zrzutów ekranu z takich miejsc:
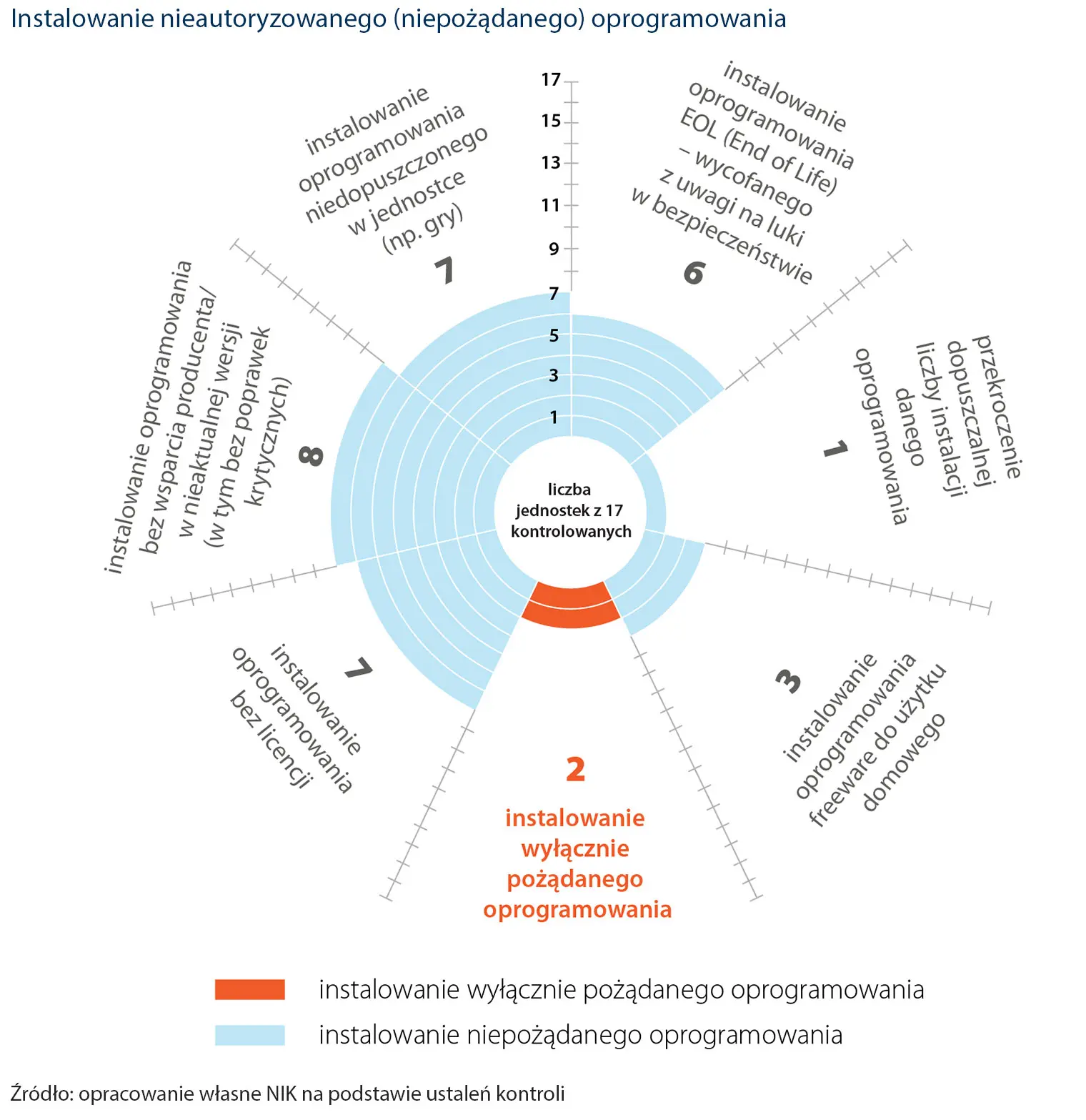
 Zestawienie wycieków z jednego tygodnia
Zestawienie wycieków z jednego tygodniaPowyżej zestawienie udostępnionych wycieków z okresu około tygodnia na jednym tylko forum. Co więcej, są to wyłącznie dane w łatwym do przetwarzania formacie tekstowym LOGIN:HASŁO. Udostępnianych baz jest natomiast dużo więcej. Niektóre z nich w formie plików .sql wymagających zaimportowania do bazy, inne zawierają hasła w formie hashy, które trzeba poddać łamaniu.
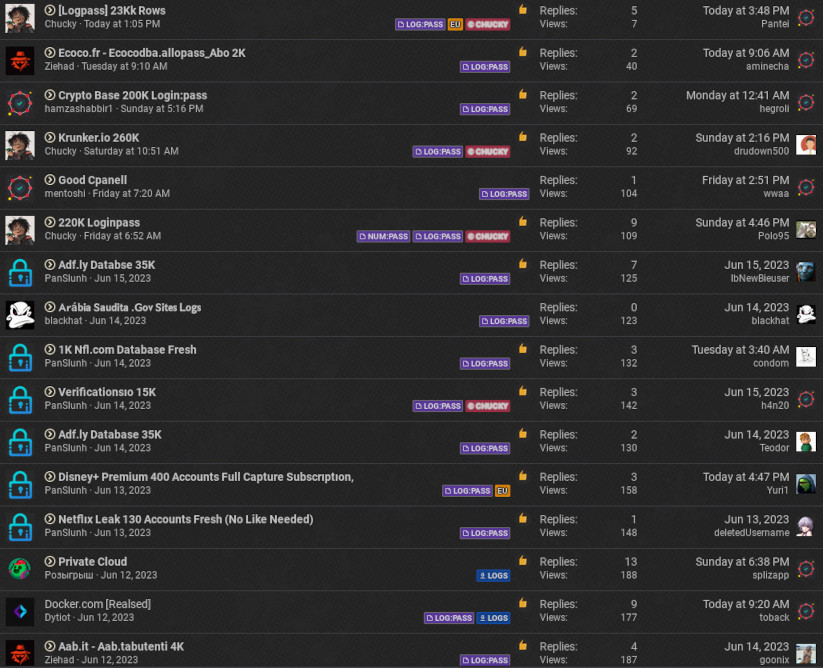
Poniżej inne zestawienie pokazujące jak wiele danych może się znaleźć w takim wycieku:
widzimy zatem, iż wycieki zawierające miliony lub choćby dziesiątki milionów haseł nie są niczym niezwykłym. Co gorsza, powyższe zestawienie pochodzi z czarnorynkowego sklepu, gdzie większość z baz można nabyć za cenę z przedziału 20$-50$.
Legalność przetwarzania
Wiemy już, iż wycieki są częste i zawierają ogromne ilości danych. Wiemy też iż są ogólnodostępne. Ale czy to znaczy, iż każdy z nas może takie pliki pobrać chcąc np. sprawdzić czy znajdują się w nim jego dane? Nie bardzo. Plik zawierający miliony rekordów użytkowników, choćby jeżeli są to tylko loginy i hasła stanowi zbiór danych osobowych. choćby jeżeli login nie jest adresem e-mail, to logując się na konto danego użytkownika bylibyśmy w stanie w większości przypadków ustalić jego tożsamość na podstawie danych zawartych w profilu.
W myśl przepisów o ochronie danych osobowych, dane osobowe to również takie dane, które pozwalają na pośrednie ustalenie tożsamości. I w myśl tych samych przepisów pobieranie, kopiowanie, otwieranie czy choćby samo zaglądanie do pliku jest już przetwarzaniem danych osobowych. A do tego, nie wdając się już w szczegóły, musimy mieć albo podstawę prawną, albo zgodę właściciela danych.
Warto też wspomnieć o przepisach kodeksu karnego, jak np.:
Art. 267
§ 1. Kto bez uprawnienia uzyskuje dostęp do informacji dla niego nieprzeznaczonej, otwierając zamknięte pismo, podłączając się do sieci telekomunikacyjnej lub przełamując albo omijając elektroniczne, magnetyczne, informatyczne lub inne szczególne jej zabezpieczenie, podlega grzywnie, karze ograniczenia wolności albo więzienia do lat 2.
Więcej na ten temat pisałem w artykule pt. „Przestępstwo komputerowe – definicja„. Tutaj przytoczę jeszcze tylko jeden zapis z kodeksu karnego, który istotny jest dla osób zawodowo zajmujących się testami bezpieczeństwa:
Art.269c
Nie podlega karze za przestępstwo określone w art. 267 § 2 lub art. 269a, kto działa wyłącznie w celu zabezpieczenia systemu informatycznego, systemu teleinformatycznego lub sieci teleinformatycznej albo opracowania metody takiego zabezpieczenia i niezwłocznie powiadomił dysponenta tego systemu lub sieci o ujawnionych zagrożeniach, a jego działanie nie naruszyło interesu publicznego lub prywatnego i nie wyrządziło szkody.
Na podstawie powyższego zapisu osoby takie jak pentesterzy lub specjaliści odpowiedzialni za cyberbezpieczeństwo mogą w teorii pozwolić sobie na nieco więcej niż przeciętny użytkownik Internetu. W teorii, bo w sądzie sprawy mogą już przyjąć różny obrót i niczego nie można z góry uznawać za przesądzone.
Dla ostrzeżenia dodam, iż autorzy wspomnianego wcześniej zbioru Collection1 zostali aresztowani przez Europol. Jeden z nich na terenie Polski.
Nie jest jednak tajemnicą, iż działy bezpieczeństwa w dużych firmach oraz pentesterzy często przetwarzają takie pliki. Wyobraźmy sobie taką sytuację – klient zamawia u nas usługę taką jak np. testy bezpieczeństwa, analizę ryzyka lub threat modeling. Czy możemy ją wykonać rzetelnie pomijając fakt, iż gdzieś tam po Internecie krążą hasła z jego systemów lub należące do jego pracowników? Ja osobiście wykonując jakąkolwiek usługę z zakresu cyberbezpieczeństwa przeglądam kilka popularniejszych baz pod kątem adresów e-mail należących do domeny klienta. W minionym tygodniu znalazłem w takiej bazie około 700 adresów email z hasłami w domenie firmy, dla której wykonywałem usługi. Dzięki temu użytkownicy zostali ostrzeżeni, a ich hasła zresetowane. Pomijając ten krok utwierdziłbym klienta w złudnym przekonaniu, iż dane w jego systemach są bezpieczne.
Jak przetwarzać dane z wycieków?
Wiecie już, iż lepiej tego nie robić nie mając bardzo konkretnych przesłanek. Zakładam jednak, iż wśród czytelników mojego bloga mogą się znaleźć osoby, które są umocowane do tego by pliki z wyciekami danych przetwarzać. Załóżmy, iż jesteście pracownikami firmy świadczącej usługi online i dowiedzieliście się, iż w Internecie dostępny jest plik zawierający dane waszych klientów. Jak taki plik otworzyć, przeszukać, przefiltrować, posortować lub wyciągnąć z niego przydatne statystyki? Opanowania należy życzyć temu, kto taki plik tekstowy o wielkości kilku GB czy choćby kilkuset MB będzie próbował otworzyć w notatniku. Gdy już zabijecie proces notatnika lub zrestartujecie komputer, zapoznajcie się z poniższymi wskazówkami.
Narzędzia do przetwarzania dużych plików tekstowych
Środowiskiem idealnym do przetwarzania wielkich plików tekstowych wydaje się być Linux. Głównie ze względu na fakt domyślnie w nim wstępujących narzędzi terminalowych, które są bardzo wydajne, potrafią przetwarzać pliki nie ładując ich w całości do pamięci i pozwalają na wykorzystywanie ich w potokach lub jako filtrów. jeżeli na tym etapie nie wiecie o co chodzi, nie przejmujcie się, poniżej będą przykłady.
Poza tym, jak mawiają, Linux nieskończoną pętlę robi w 5 sekund
Przeglądanie pliku z wyciekiem
Wiemy już, iż ogromnego pliku tekstowego nie da się otworzyć w notatniku (tyczy to się również większości graficznych edytorów tekstu pod Linuksem). Na dzień dobry by zajrzeć do pliku możemy więc użyć polecenia more. Wyświetli nam ono pierwsze kilkadziesiąt linii pliku i pozwoli na jego przewijanie – enterem o jedną linię, spacją o jeden ekran. W przykładzie posłużmy się plikiem PL.txt, który stanowi rzekomo zbiór 6 milionów loginów i haseł Polaków, o którym głośno było pod koniec maja 2023r.
more PL.txt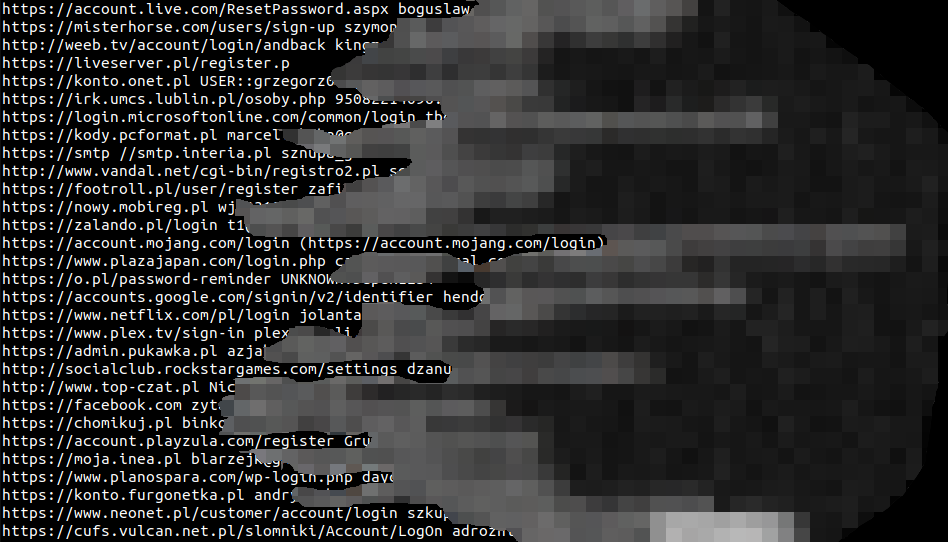 pierwsze kilkadziesiąt linii pliku PL.txt
pierwsze kilkadziesiąt linii pliku PL.txtNa tym etapie widzimy, iż format pliku jest następujący:
adres_strony login:hasło
Jednak odnalezienie konkretnych danych w pliku o rozmiarze 438MB poprzez jego przeglądanie jest zadaniem karkołomnym. Dla uzmysłowienia sobie wielkości tego pliku możemy przytrzymać wciśniętą spację powodując ciągłe, natychmiastowe przewijanie o pełen ekran. Po ponad minucie nastąpi przeskok z 0% na 1% całości pliku (more wyświetla tę statystykę u dołu ekranu). Oczywiście nie ma to większego sensu. Wyświetlamy bowiem po około 50 linii z pliku mającego ich ponad 6 milionów. Musielibyśmy więc wcisnąć spację 120 tys. razy lub trzymać ją wciśniętą przez jakieś 100 minut żeby przejrzeć cały plik. Ale skąd wiemy ile wierszy danych ma taki plik? Ponieważ w Linuksie mamy polecenie wc (word count), które zlicza nam słowa w pliku tekstowym, a z parametrem -l zwraca nam ilość linii w takim pliku:
> wc -l PL.txt 6274679 PL.txtNas jednak w tym momencie najbardziej nurtuje pytanie, czy w pliku znajdują się nasze dane. I tutaj z pomocą przychodzi nam grep. Jest to potężne narzędzie pozwalające wyłuskiwać z pliku lub wejścia potoku dane m.in. dzięki wyrażeń regularnych. W naszym przypadku będzie to jednak dużo prostsze bo interesuje nas proste wyrażenie zawierające naszą nazwę użytkownika lub email. Załóżmy, iż posługujemy się adresem e-mail [email protected]. Wyszukiwanie przeprowadzimy w następujący sposób:
> grep [email protected] PL.txtEwentualnie jeżeli interesują nas wszystkie maile z naszej domeny (domena_firmowa.com) będzie to:
> grep domena_firmowa.com PL.txtNa co tutaj warto zwrócić uwagę, to fakt, iż wyszukiwanie w pliku mającym ponad 6 mln. wierszy zwróciło nam wynik praktycznie natychmiast. Możemy to choćby dokładnie zmierzyć używając również dostępnego domyślnie w Linuksie polecenia time:
> time grep domena_firmowa.com PL.txt real 0m0,347s user 0m0,259s sys 0m0,088sPrzeszukanie trwało 0,347 sekund. Szaleństwo!
No dobra, to co jeszcze interesującego możemy się dowiedzieć z takiego pliku? Załóżmy, iż chcielibyśmy zweryfikować ilu użytkowników, których dane wyciekły używało hasła „qwerty”. To będzie dobry przykład by zaprezentować działanie filtrów i potoków, czyli przekazywanie wyjścia jednego polecenia na wejście innego. Poniżej wyszukujemy interesujące nas hasła w pliku (grep) i jednocześnie zliczamy ile ich było przepuszczając wyjście tego polecenia przez polecenie wc -l :
> grep qwerty PL.txt | wc -l 14463Jeśli myślicie, iż 14463 użytkowników korzystało z hasła 'qwerty’ to nie wzięliście pod uwagę drobnego szczegółu. Otóż wyszukaliśmy wszystkie linie zawierające ciąg 'qwerty’ w dowolnym miejscu, czyli również jako fragment nazwy domeny lub nazwy użytkownika, a także hasła typu 'qwerty123′. Dlatego używając przetwarzania potokowego dobrą praktyką jest wykonać najpierw każde polecenie z osobna i dopiero dodawać kolejne. Dzięki temu zobaczylibyśmy co tak na prawdę zwraca nam ’grep qwerty PL.txt’ zanim wynik zostanie policzony ’wc -l’.
Aby policzyć to dokładniej posłużymy się w ciągu wyszukiwania znakiem dwukropka, ponieważ od niego rozpoczynają się w pliku hasła oraz znakiem $, który w wyrażeniach regularnych oznacza koniec linii:
> grep :qwerty$ PL.txt | wc -l 0Dlaczego polecenie to zwróciło nam 0 wyników? Czyżby żaden z 6 milionów użytkowników nie używał jednego z najpopularniejszych haseł? Niezupełnie. Natknęliśmy się tutaj na inny problem. Otóż znak $ w poleceniu grep wyszukuje tzw. uniksowy koniec linii (stosowany też w Linuxach i macOS 10+). Pliki pochodzące z wycieków mogą natomiast pochodzić z różnych systemów operacyjnych i być zapisywane z użyciem różnych narzędzi (również pod Windowsem). Aby zrobić z tym porządek możemy przepuścić zawartość pliku przez filtr (polecenie) tr , które usunie z niego windowsowy znak końca linii:
> cat PL.txt | tr -d '\r' > PLu.txtWidoczne powyżej polecenie cat wyświetla całą zawartość pliku PL.txt ale zamiast na ekran przekazujemy ją z użyciem filtra | do polecenia tr, którego parametr -d usuwa po drodze wszystkie wystąpienia '\r’ (ponieważ windowsowy koniec linii reprezentowany jest jako \r\n, a uniksowy jako \n). Na końcu wynik zamiast na konsolę przekierowywany jest do nowego pliku > PLu.txt. Mamy już plik z odpowiednim uniksowym znakiem końca linii, spróbujmy zatem ponownie policzyć hasła 'qwerty’:
> grep :qwerty$ PLu.txt |wc -l 1510Skoro plik zawiera dane polskich użytkowników to spróbujmy może jeszcze policzyć inne popularne hasła:
> grep :dupa$ PLu.txt |wc -l 164 > grep :dupadupa$ PLu.txt |wc -l 132 > grep :lubieplacki$ PLu.txt |wc -l 203Jeśli nie wiecie skąd popularność tego ostatniego, to pewnie nie oglądaliście kreskówki Johny Bravo Ale już wiecie, iż znane cytaty i powiedzonka to nie jest dobry patent na hasło.
Oczyszczanie danych
Być może już na pierwszym zrzucie ekranu z polecenia more zauważyliście, iż pomimo oczekiwanej struktury plik:
adres_strony login:hasło
znajdują się w nim wiersze zawierające tylko adres strony. Takich błędów jest dużo więcej. Wynika to z faktu, iż pliki te często są przetwarzane nieumiejętnie lub przez osoby nie przejmujące się błędami. Bo co to za różnica jak na 10 milionów rekordów np. 100 będzie uszkodzonych? W pliku można też znaleźć miejsca, gdzie z jakiegoś powodu wiele wierszy zostało połączonych w jeden (prawdopodobnie błąd przetwarzania końca linii):
 przykład bardzo długiej linii w pliku PL.txt
przykład bardzo długiej linii w pliku PL.txtTrochę może nam to przeszkadzać w dalszym przetwarzaniu więc warto oczyścić plik z takich przypadkowych wierszy. W większości nie zawierają one parametrów login i hasło lub zawierają je na nieoczekiwanych dalekich pozycjach i to za każdym razem różnych.
Załóżmy, iż jako niechciane interesują nas linie o długości powyżej 300 znaków. Maksymalna długość nazwy domeny to 64 znaki. Załóżmy, iż z subdomeną i ścieżką oraz parametrami przekazywanymi w URL-u adres strony może mieć jakieś 200-250 znaków (choć sporadycznie zdarzają się i znacznie dłuższe). Do tego login, który często jest adresem mailowym i hasło. 300 znaków powinno wystarczyć. Jak usunąć z pliku wiersze o długości większej niż oczekiwana? Najpierw spróbujmy je wyszukać poleceniem ’grep’:
> grep '.{300}' PLu.txtgrep '.{300}' PLu.txt > dlugie.txtKropka w powyższym wyrażeniu regularnym oznacza dowolny znak, a wartość 300 w nawiasach klamrowych, iż interesuje nas minimum 300 wystąpień tego (dowolnego) znaku. Wszystkie wiersze z pliku PLu.txt spełniające ten warunek zostaną wylistowane, a wyjście polecenia przekierowane do pliku 'dlugie.txt’. Plik ten możemy teraz przejrzeć i jeżeli uznamy, iż rzeczywiście znajdują się w nim mało przydatne dane przejdziemy do ich usunięcia z pliku głównego. Z ciekawości zerknijmy jeszcze ile takich długich wierszy znalazło się w pliku 'dlugie.txt’:
> wc -l dlugie.txt 5049 dlugie.txtPlik 'dlugie.txt’ nie będzie nam już potrzebny. Posłużył on tylko jako plik tymczasowy do zweryfikowanie ile i jakich danych pozbędziemy się eliminując wiersze o długości powyżej 300 znaków. Aby dane te usunąć z pliku głównego możemy np. odwrócić zapytanie i wylistować z niego wszystkie linie niespełniające tego warunku. Polecenie grep ma do tego specjalny parametr -v . Wynik przekierowujemy do nowego pliku 'PLu300.txt’:
> grep -v '.{300}' PLu.txt > PLu300.txtUpewnijmy się jeszcze, iż nowy plik jest rzeczywiście tylko o 5049 linii krótszy od pierwotnego:
> wc -l PLu300.txt 6269630 PLu300.txtWygląda w porządku.
Praca na kolumnach
Plik z wyciekiem danych może nam posłużyć do stworzenia ciekawych statystyk dotyczących np. popularności haseł bądź serwisów internetowych. Żeby jednak te statystyki opracować musimy wyciągnąć poszczególne kolumny pliku (strona, login, hasło) do oddzielnych plików. Tutaj z pomocą przyjdzie nam kolejne narzędzie do przetwarzania tekstu – ’awk’ :
> awk '{ print $1 }' PLu300.txt > PLu300-adresy.txtAWK to prawdziwy kombajn to przetwarzania tekstu. Systemowy manual do niego ma kilkadziesiąt stron i nie jesteśmy w stanie omówić go tutaj szczegółowo. Skupmy się zatem tylko na powyższym przykładzie. Polecenie ’print $1′ przekazywane jako parametr oznacza, iż z każdej linii pliku ma nam zostać zwrócona jedynie pierwsza kolumna. Po wykonaniu powyższego polecenia w pliku PLu300-adresy.txt będziemy zatem mieli wszystkie adresy stron, do których loginy i hasła znalazły się w wycieku. Dla pewności zerknijmy sobie na pierwsze 10 linii tego pliku poznając kolejne przydatne polecenie: ’head’:
> head PLu300-adresy.txt https://account.live.com/ResetPassword.aspx https://misterhorse.com/users/sign-up http://weeb.tv/account/login/andback https://liveserver.pl/register.p https://konto.onet.pl https://irk.umcs.lublin.pl/osoby.php https://login.microsoftonline.com/common/login https://kody.pcformat.pl https://smtp http://www.vandal.net/cgi-bin/registro2.plAnalogicznie do ’head’ możemy użyć polecenia ’tail’, które zwróci nam ostatnie 10 linii pliku:
> tail PLu300-adresy.txt http://chomikuj.pl/Zdziwko/Gry+na+PC/Don27t+Starve+5bcic485gle+aktualizowany*5d http://profesor.pl/forum/register.php https://allegro.pl/login https://zdamyto.com http://www.fileshark.pl/premium/kup http://m.o2.pl https://platforma.epodreczniki.pl/account/login http://www.mynavi-expert.pl/index.php https://www.goip.de/security/loginfailed https://www.frisco.plZarówno head, jak i tail mogą nam zwrócić inną niż domyślna liczbę wierszy zdefiniowaną poprzez parametr -n:
> head -n 3 PLu300-adresy.txt https://account.live.com/ResetPassword.aspx https://misterhorse.com/users/sign-up http://weeb.tv/account/login/andbackPowyższe wyniki pokazują, iż zawartość pliku z adresami stron jest z grubsza w porządku, jednak spostrzegawczy zauważyli być może, iż w jednej z linii wystąpiła wartość ’https://smtp’, która nie jest prawidłowym adresem strony. Wynika to z faktu, iż wiersz ten w oryginale miał poniższą zawartość:
https://smtp //smtp.interia.pl uzytkownik:haslo
A zatem jego pierwsza kolumna jest błędna. Jak już wcześniej wspomniałem tego typu śmieciowe dane często spotykane są w dużych plikach. Musimy je podczas przetwarzania korygować lub usuwać. Macie pomysł jak wyłapać takie błędne adresy stron? Możemy np. wyszukać wszystkie wiersze nie zawierające żadnego znaku kropki. Bazując na dotychczasowych przykładach chciałoby się użyć polecenia:
> grep -v . PLu300-adresy.txtJednak powyższe polecenie w rzeczywistości nie zwróci nam żadnego wyniku. Pamiętajcie, iż grep wyszukiwane wartości traktuje jako wyrażenia regularne. A wspominałem już wcześniej, iż w wyrażaniach regularnych kropka oznacza dowolny znak. Wyszukaliśmy więc tak naprawdę wszystkie wiersze niezawierające żadnego znaku.
Jeśli chcemy by grep interpretował znaki specjalne takie jak kropka, $ (koniec linii), ^ (początek linii) dosłownie, musimy je poprzedzić znakiem backslash-a (\ ). Przy okazji policzmy (wc -l) ile wierszy zwróci nam prawidłowe wyszukiwanie:
> grep -v '\.' PLu300-adresy.txt | wc -l 20264Jak widać mamy ponad 20 tys. wierszy, które nie wyglądają na prawidłowy adres strony. By się ich pozbyć, znowu odwracamy zapytanie (czyli pomijamy parametr -v) i przekierowujemy wynik do nowego pliku:
> grep '\.' PLu300-adresy.txt > PLu300-adresy2.txtTutaj małe wyjaśnienie – dlaczego tak często tworzymy nowe pliki, czy jest to niezbędne? Nie. Moglibyśmy używać poleceń i składni, która modyfikuje bezpośrednio pliki źródłowe. Praktyka nauczyła mnie jednak, iż jeżeli popełnimy gdzieś błąd i zepsujemy sobie plik z danymi, to lepiej jest mieć pliki tworzone na każdym poprzednim etapie. Łatwiej wówczas cofnąć się o jeden lub kilka kroków zamiast rozpoczynać całe przetwarzanie od nowa.
Statystki – sortowanie, grupowanie i zliczanie
Jakie interesujące dane możemy wyciągnąć z pliku zawierającego ponad 6 milionów adresów stron, do których logowali się użytkownicy? Zobaczmy na początek jak to jest z tym bezpieczeństwem w sieciach publicznych. Mówi się, iż publiczne WiFi nie są już tak dużym zagrożeniem jak kiedyś, ponieważ teraz cały ruch odbywa się po szyfrowanym protokole HTTPS. Policzmy zatem:
> grep https PLu300-adresy2.txt | wc -l 5456504 > grep -v https PLu300-adresy2.txt | wc -l 792862Prawie 5,5 mln stron, do których logowano się po HTTPS kontra prawie 800 tys., do których logowano się po HTTP. Czyli jakieś 14,5% logowań przez cały czas odbywa się w sposób nie gwarantujący bezpieczeństwa. Trochę więc potwierdza się to, o czym pisałem w artykule pt. (nie)Bezpieczeństwo publicznych sieci WiFi.
Najpopularniejsze strony
Jeśli od aspektów bezpieczeństwa bardziej interesują nas np. biznesowe, możemy spróbować policzyć jakie serwisy www są najpopularniejsze wśród Polaków. W końcu 6 milionów adresów może się wydawać dobrą grupą reprezentatywną do tego typu obliczeń.
Na tym etapie przydadzą nam się dwa nowe polecenia: ’sort’ oraz ’uniq’. Pierwsze z nich sortuje nam plik, drugie wyświetla, a przy okazji też zlicza wyłącznie unikalne wiersze tego pliku. Musimy je zastosować właśnie w takiej kolejności ponieważ ’uniqu’ nie potrafi zliczać wartości nieposortowanych. Zacznijmy zatem od sortowania:
> sort PLu300-adresy2.txt > PLu300-adresy2-posortowane.txtMamy nowy plik z posortowanymi adresami. Przy użyciu 'uniq’ wyciągniemy teraz z niego tylko unikalne wiersze, ale jednocześnie dzięki parametrowi -c dowiemy się ile było wystąpień każdego z nich:
> uniq -c PLu300-adresy2-posortowane.txt > PLu300-adresy2-policzone.txtOtrzymany plik będzie miał format:
X adres_strony
gdzie X to ilość wystąpień danego adresu w posortowanym pliku wejściowym. Żebyśmy jednak nie musieli manualnie przeglądać pliku wynikowego (ma on ponad milion wierszy) w poszukiwaniu największych wartości X, możemy go ponownie posortować:
> sort -r PLu300-adresy2-policzone.txt > PLu300-adresy2-policzone-naj.txtTym razem jednak do sortowania użyłem dodatkowego parametru -r (reverse), który spowodował odwrotne sortowanie. Dzięki temu w pliku wynikowym najpopularniejsze strony (z największą wartością pierwszej kolumny) będę miał na początku. Sprawdźmy zatem jak wygląda 10 najpopularniejszych stron w Polsce:
> head PLu300-adresy2-policzone-naj.txt 80935 https://forum.plutonium.pw/register 45626 https://profil.wp.pl/login.html 41705 https://api.librus.pl/OAuth/Authorization 30014 https://1fichier.com/register.pl 27458 https://allegro.pl/login/form 25157 https://www.facebook.com 23822 https://secure7.playpark.com/authen_gateway/inpp/login_default.aspx 21955 https://app.plex.tv/auth 21531 https://app.plex.tv/auth-form 21398 https://www.planetside2.com/registerNiby ok, ale jednak coś tutaj nie gra. Poza WP, Allegro i Librusem w zestawieniu znalazły się nieznane mi serwisy zagraniczne, głównie dla graczy. Podobnie wygląda to na dalszych pozycjach. Początkowo z tego zestawienia wyciągnąłem błędny wniosek, iż wycieki pochodziły głównie z komputerów osób młodych interesujących się grami komputerowymi. Ktoś jednak zwrócił mi uwagę (dzięki Adam ), iż cechą wspólną tych adresów jest występowanie w nich ciągu znaków „.pl„:
- https://forum.plutonium.pw/register
- https://1fichier.com/register.pl
- https://app.plex.tv/auth
- https://www.planetside2.com/register
Co to oznacza? Tutaj konieczne jest krótkie wyjaśnienie. Plik stanowiący zestawienie haseł Polaków (PL.txt) nie powstał poprzez świadome i celowe infekowanie komputerów wyłącznie polskich użytkowników. Został on wygenerowany poprzez odfiltrowanie stealer logów zawierających dane również innych internautów. I najwidoczniej jego autor popełnił prosty błąd. Użył polecenia ’grep’ do wyszukania wszystkich polskich domen w taki sposób:
> grep '\.pl' stealer_logs.txtCo w efekcie spowodowało, iż w wynikach znalazły się nie tylko domeny z końcówką „.pl„, ale też te, w których „.pl” występuje w jakimkolwiek innym miejscu. Żeby potwierdzić tę tezę zerknijmy jak wyglądają nazwy użytkowników (pierwsze 50) np. dla domeny „app.plex.tv” w pliku źródłowym PL.txt:
> grep 'app.plex.tv' PL.txt | head -n 50Wyników nie mogę Wam zaprezentować ponieważ zawierają adresy e-mail, ale z obecnych w nich imion (np. Vincent, Jesus, Hillary, Jeane, Tiffany, Yumi itd.) zdecydowanie możemy wywnioskować, iż nie są to użytkownicy z Polski.
Wróćmy zatem do naszego pliku z najpopularniejszymi domenami i wyciągnijmy z niego wyłącznie te adresy, w których ciąg znaków „.pl” występował na końcu wiersza (\.pl$) lub bezpośrednio przed znakiem „/” (\.pl/). Użyjemy do tego operatora LUB w postaci znaku „|”. Ale uwaga, musimy też poprzedzić go znakiem backslash. Tym razem jednak nie po to by grep traktował go dosłownie, ale by nie został on zinterpretowany przez powłokę systemową jako symbol potoku (połączenie wyjścia jednego polecenia z wejściem drugiego):
> grep '\.pl/\|\.pl$' PLu300-adresy2-policzone-naj.txt > PLu300-adresy2-policzone-naj-pl.txtWiem, tutaj można się trochę pogubić z tymi backslash-ami. Chodzi o to, iż polecenie, które wpisujemy w konsoli jest najpierw interpretowane przez samą powłokę systemową, a w niej | oznacza symbol potoku. Poprzedzając go backslash-em powodujemy, iż nie jest on interpretowany przez powłokę, a dopiero przez polecenie grep. Gdybyśmy chcieli żeby również grep nie interpretował znaku | jako operatora LUB, a potraktował go dosłownie jako symbol do wyszukania, musielibyśmy poprzedzić go podwójnym znakiem backslash: \\.
A teraz, zerknijmy do naszego zestawienia najpopularniejszych adresów w domenie .pl:
> head PLu300-adresy2-policzone-naj-pl.txt 45626 https://profil.wp.pl/login.html 41705 https://api.librus.pl/OAuth/Authorization 30014 https://1fichier.com/register.pl 27458 https://allegro.pl/login/form 16219 https://skmedix.pl/sklauncher/register 15358 https://www.olx.pl/konto 14910 https://chomikuj.pl 14447 https://www.onet.pl/poczta 14276 https://poczta.o2.pl/zaloguj 13930 https://poczta.interia.plJest już lepiej, ale w zestawieniu wkradł się jeszcze jeden błąd. Znalazły się w nim adresy takie jak: „https://1fichier.com/register.pl„, gdzie końcówka „.pl” nie oznacza domeny głównej, a rozszerzenie pliku na serwerze. Jak moglibyśmy się pozbyć takich przypadków? Spróbujmy tak:
grep -v '://.*/.*\.pl' PLu300-adresy2-policzone-naj-pl.txt > naj-domeny-pl.txtWyjaśnijmy sobie wyrażenie ’://.*/.*\.pl’ podane jako parametr dla grep rozbijając je na części:
- :// – oznacza dosłownie ciąg znaków „://” występujący w adresie po http lub https (np. https://)
- .* – kropka oznacza dowolny znak (bo nie jest poprzedzona backslash-em), a gwiazdka dowolną ilość wystąpień tego znaku (np. https://costam.costam)
- /.* – znak slash dosłownie, a po nim znowu dowolny znak występujący dowolną ilość razy (np. https://costam.costam/costam)
- \.pl – symbol kropki (dosłownie, bo poprzedzony backslash-em) a po nim ciąg „pl” (np. https://costam.costam/costam.pl)
Po złożeniu w całość mamy więc wyrażenie oznaczające wartości typu ://costamcostam/costam.pl. A ponieważ w zapytaniu użyliśmy parametru -v, do pliku wynikowego trafią wszystkie wiersze, które do powyższego wzorca nie pasują.
Zerknijmy zatem wreszcie na ostateczne (czy aby na pewno?) zestawienie tych najpopularniejszych domen .pl:
> head -n 50 naj-domeny-pl.txt 45626 https://profil.wp.pl/login.html 41705 https://api.librus.pl/OAuth/Authorization 27458 https://allegro.pl/login/form 16219 https://skmedix.pl/sklauncher/register 15358 https://www.olx.pl/konto 14910 https://chomikuj.pl 14447 https://www.onet.pl/poczta 14276 https://poczta.o2.pl/zaloguj 13930 https://poczta.interia.pl 12884 https://1login.wp.pl/zaloguj/dodaj 12657 https://nowyprofil.wp.pl/rejestracja 12606 https://profil.wp.pl 11830 https://profil.wp.pl/login/login.html 10195 https://pz.gov.pl/dt/login/login 9150 https://allegro.pl 8827 https://www.o2.pl 8541 https://konto.onet.pl/login.html 8388 https://allegro.pl/rejestracja 8340 https://poczta.o2.pl 8031 https://allegro.pl/logowanie 8012 http://chomikuj.pl 7886 https://poczta.interia.pl/logowanie 7321 https://konto-pocztowe.interia.pl 7284 https://skmedix.pl/sklauncher/login 7042 https://konto.onet.pl 7037 https://ssl.allegro.pl/login/form 6874 https://ssl.allegro.pl/fnd/authentication 6365 https://konto.onet.pl/register-email.html 6292 https://konto.onet.pl/auth.html 6267 https://api.librus.pl/oauth/authorization 5871 https://tipply.pl/register 5705 https://instaling.pl/teacher.php 5695 https://profil.wp.pl/login_poczta.html 5682 https://logowanie.play.pl/p4-idp2/SSOrequest.do 5656 https://www.cshacked.pl/rejestracja 5591 https://www.cshacked.pl/zaloguj 5557 https://moja.biedronka.pl 5523 https://cm-pack.pl/panel/signup.php 5395 https://www.amazon.pl/ap/signin 5353 https://olx.pl/konto 5284 https://nk.pl 5223 https://onet.pl/poczta 5223 https://konto.play.pl/opensso/logowanie 5200 https://m.olx.pl/konto 5102 https://poczta.o2.pl/rejestracja 4967 https://moja.biedronka.pl/rejestracja 4758 https://ssl.allegro.pl 4678 https://www.x-kom.pl/logowanie 4631 https://online.mbank.pl/pl/Login 4479 https://login.pracuj.plNadal może to nie być wynik satysfakcjonujący dla kogoś, kto chciałby np. zrobić porównanie typu Onet.pl vs WP.pl albo Allegro.pl vs OLX.pl. Widzimy bowiem, iż w pliku mamy różne subdomeny tych popularnych dostawców usług. Należałoby je więc zliczyć i zsumować. Ale na tym poprzestaniemy bo bazując na wcześniejszych przykładach powinniście sobie już dać radę. My zajmiemy sę natomiast innymi statystykami.
Najpopularniejsze hasła
Spróbujmy teraz podobne statystyki wyciągnąć w odniesieniu do haseł zawartych w udostępnionym pliku z wyciekami. W poprzednim punkcie interesowała nas pierwsza kolumna tego pliku. Przypomnijmy, iż jego format jest następujący:
adres_strony login:hasło
Problemem może się wydawać fakt, iż hasło od loginu nie jest oddzielone spacją, więc stanowi tylko fragment drugiej kolumny pliku. Na szczęście polecenie awk pozwala nam zdefiniować dzięki parametru -F jaki znak będziemy traktować jako separator kolumn. Domyślnie jest to spacja, ale my możemy wymusić, iż w tym wypadku będzie to znak dwukropka:
> awk -F : '{ print $3 }' PLu300.txt > hasla.txtDlaczego wybieramy 3. kolumnę? Ponieważ dwukropek występuje też w adresie strony. Przykładowo więc, dla wiersza:
https://jakas-strona.pl jakub:tajnehaslo
pierwszą kolumnę będzie stanowił ciąg: „https„, drugą ciąg:”jakas-strona.pl jakub”, a trzecią „tajnehaslo„. W pliku hasla.txt mamy więc wszystkie hasła. Zobaczmy teraz jak z użyciem potoków możemy wszystkie wykonywane wcześniej operacje sortowania i zliczania połączyć w jedno polecenie:
> sort hasla.txt | uniq -c | sort -r > hasla-naj.txtOczywiście moglibyśmy to połączyć w całość również z krokiem poprzednim, w którym wybieraliśmy kolumnę z hasłami:
> awk -F : '{ print $3 }' PLu300.txt | sort | uniq -c | sort -r > hasla-naj.txtAle jeszcze raz powtórzę, iż moim zdaniem lepiej jest wykonywać te operacje krok po kroku zapisują dane do plików pośrednich i weryfikując co się w nich pojawia przed poddaniem ich dalszemu przetwarzaniu. Wówczas dużo łatwiej wychwycimy błędy.
W pliku hasla-naj.txt znalazło się trochę danych, które hasłami raczej nie są, a wskazują na to, iż w miejscu gdzie miało być hasło znalazł się pusty ciąg lub jakaś wartość niezdefiniowana:
31409 NULL14786 ?
4428 None
2042 UNKNOWN
1932 User Data Default
1732 USER
Po ich odfiltrowaniu zestawienie 100 najpopularniejszych haseł prezentuje się następująco (pierwsza kolumna oznacza ilość wystąpień danego hasła, druga samo hasło):
10963 123456 3540 12345678 3399 123456789 3392 admin 3221 123qwe 3045 Xperiaj1 2790 zaq1@WSX 2733 Homo1008 2693 zaq12wsx 2347 1234 2244 Adzio2020 2023 12345 1903 1234qwer 1809 password 1731 Rezyser2 1633 Anna1234 1630 P@ssw0rd 1532 123 1421 qwerty 1385 Jolinachiara1 1378 1234qweR 1331 qwerty123 1275 1234567890 1151 https 1051 111111 1050 Ztgwh700 993 czaja1982 927 1qaz2wsx 916 1 889 Natalka2015 887 bumer1986 881 Milenka11 879 asiunia1 863 123123 821 1q2w3e4r 816 torcida99 799 Adzio2019 778 Mrclyde11 771 hugohugo123 749 sdfoiu 738 261281 719 Bedysz!972 710 Qwerty123 704 lol123 696 sebek123 685 tomson21 684 1234567 673 ZAQ!2wsx 659 haslo123 647 PASS 638 kamilek1 634 Mateusz1 630 rokita135 623 123456789a 614 SpecSoft21 608 1qazXSW@ 606 fb-login 602 Hasło 601 page 600 polska123 594 Kacper123 592 root 591 lolek123 591 1qazxsw2 590 Bartek123 582 Polska123 575 Zaq12wsx 572 kamilekl12 571 bartek1 568 qwerty12 568 Chrome 564 Adzio2021 562 1qaz2wsx3edc 547 Url 546 a 544 dawid123 544 azazel123 541 wloszek 536 placek33 533 mateusz1 530 teklis 522 Fuckerz21 519 agnieszka 516 haslo 506 Haslo123 503 Dawid123 499 Maxior997! 499 Azazel123 498 polska 498 Mateusz12 496 Pol0909! 496 Anna1234$ 495 S#$3C3crmH 494 wino99 494 Chainski1980 492 qwerty11 491 0 490 damian1 485 1517330picasso 484 tomaszek1Większość powyższych haseł wydaje się być oczywista, ale są też wartości takie jak „1517330picasso„, których popularność może być zastanawiająca.
Podsumowanie
Jeśli macie pomysł jakie jeszcze interesujące statystyki można wyciągnąć z plików z wyciekami, podzielcie się nim w komentarzu.
Mam nadzieję, iż powyższe przykłady ułatwią Wam nieco pracę z dużymi plikami. Pamiętajcie jednak, iż wyboru dokonałem subiektywnie, a każda z omawianych operacji może być wykonana na wiele różnych sposobów. Czasem warto poeksperymentować z różnymi narzędziami jeżeli zależy nam na wydajności. Diametralne znaczenie może mieć np. kolejność wykonywanych działań.
Nie wspomniałem choćby o poleceniu ’sed’, które również może być przydatne. Podobnie jak ’awk’ stanowi ono potężne narzędzie, na temat którego pisze się całe książki.
Maruderzy zauważą pewnie, iż te same narzędzia dostępne są również na macOS-ie. OK, ale przez cały czas nie zrobi on nieskończonej pętli w 5 sekund
Zostaw e-mail aby otrzymać powiadomienia o nowościach oraz dostęp do wszystkich bonusowych materiałów przygotowanych wyłącznie dla subskrybentów.